Andy Zeng
Andy is a co-founder at Generalist. Before that, he was a research scientist and tech lead at Google DeepMind – and before that, a student at Princeton and UC Berkeley. Andy has worked on training large-scale foundation models, developing robots that write their own code, and inventing handheld data collection for robots. These days, he is interested in training large neural nets on massive amounts of robot data.
Andy Zeng is a co-founder at Generalist, where he leads a small team working on self-improving Foundation models for robots. He received his Bachelors in Computer Science and Mathematics at UC Berkeley, and his PhD in Computer Science at Princeton. He is interested in building algorithms that enable machines to intelligently interact with the world and improve themselves over time. Andy received Best Paper Awards from HRI '24, CoRL '23, ICRA '23, T-RO '20, RSS'19, and has been finalist for paper awards at RSS '23, CoRL '20 - '22, ICRA '20, RSS '19, IROS '18. He led machine learning as part of Team MIT-Princeton, winning 1st place (stow task) at the worldwide Amazon Picking Challenge '17. Andy is a recipient of the Princeton SEAS Award for Excellence, Japan Foundation Paper Award, NVIDIA Fellowship, and Gordon Y.S. Wu Fellowship in Engineering and Wu Prize. His work has been featured in the press, including the New York Times, BBC, and Wired.
X (Twitter) G. Scholar LinkedIn Github
andyzeng at generalistai dot com

2026
Generalist article "GEN-1: Scaling Embodied Foundation Models to Mastery"2025
Generalist article "GEN-0: Embodied Foundation Models That Scale with Physical Interaction"2024
IEEE Robotics and Automation (RAS) Early Career Award2023
Conference on Robot Learning (CoRL) Best Student Paper Award2022
Google AI blog post "Robots That Write Their Own Code"2020
IEEE Transactions on Robotics (T-RO) Best Paper Award2019
New York Times article "A New Lab Full of Fast Learners"{kind=link}
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, Pete Florence
International Conference on Machine Learning (ICML) 2023
Webpage •
PDF •
Demo •
Google AI Blog
Implicit Behavioral Cloning
Pete Florence, Corey Lynch, Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, Jonathan Tompson
Conference on Robot Learning (CoRL) 2021
Webpage •
PDF •
Code •
Google AI Blog
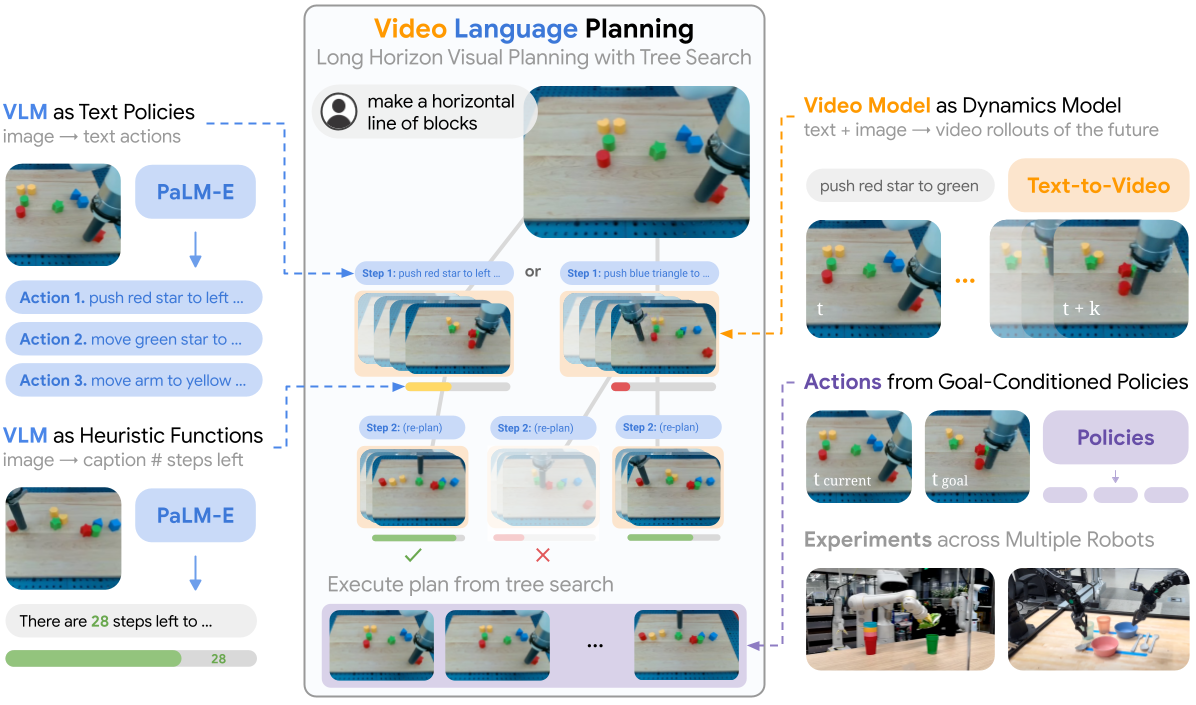
Video Language Planning
Yilun Du, Mengjiao Yang, Pete Florence, Fei Xia, Ayzaan Wahid, Brian Ichter, Pierre Sermanet, Tianhe Yu, Pieter Abbeel, Joshua B. Tenenbaum, Leslie Kaelbling, Andy Zeng, Jonathan
Tompson
International Conference on Learning Representations (ICLR) 2024
Webpage •
PDF •
Code

Code as Policies: Language Model Programs for Embodied Control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
IEEE International Conference on Robotics and Automation (ICRA) 2023
★ Outstanding Learning Paper Award, ICRA ★
Webpage •
PDF •
Code •
Colab •
Google AI Blog •
TechCrunch •
AXIOS
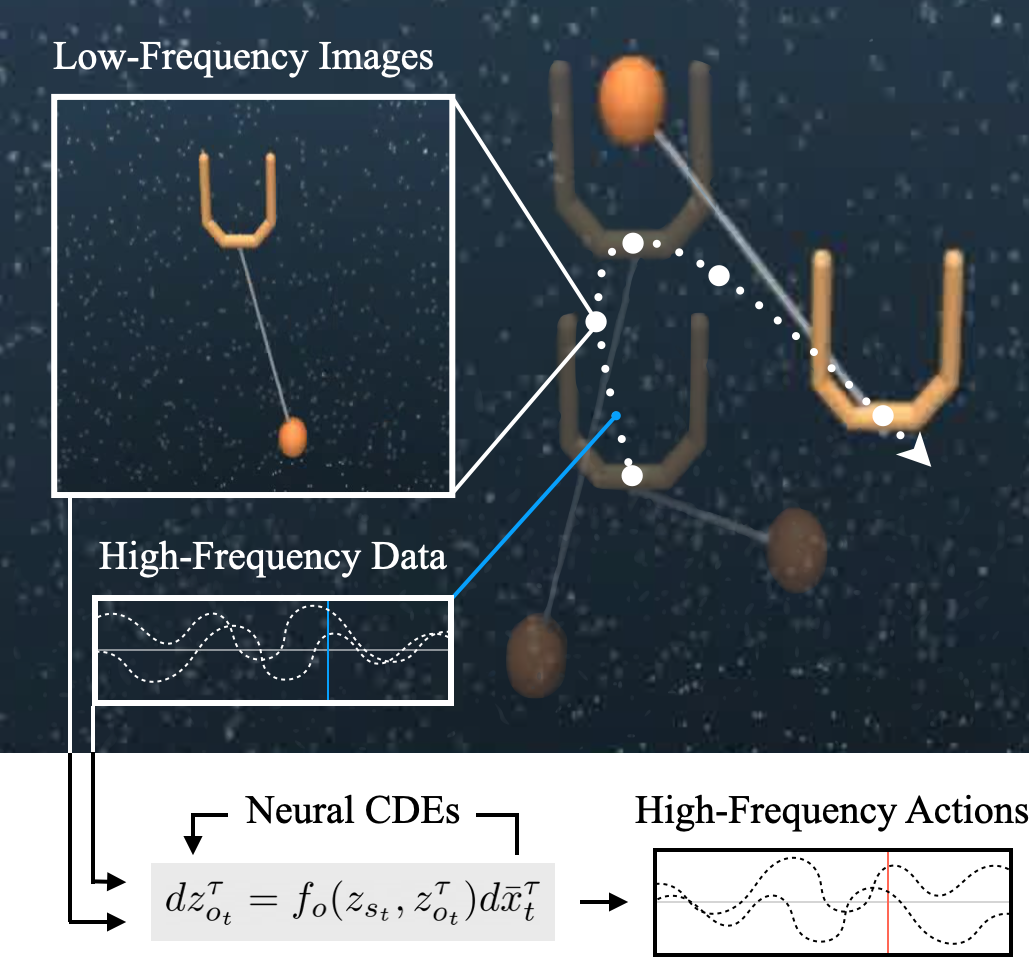
Multiscale Sensor Fusion and Continuous Control with Neural CDEs
Sumeet Singh, Francis McCann Ramirez, Jacob Varley, Andy Zeng, Vikas Sindhwani
IEEE International Conference on Intelligent Robots and Systems (IROS) 2022
PDF
Robots That Ask For Help: Uncertainty Alignment for Large Language Model Planners
Allen Z. Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, Fei Xia, Jake Varley, Zhenjia Xu, Dorsa Sadigh, Andy Zeng, Anirudha Majumdar
Conference on Robot Learning (CoRL) 2023
★ Oral Presentation, Best Student Paper Award, CoRL ★
Webpage •
PDF •
Video
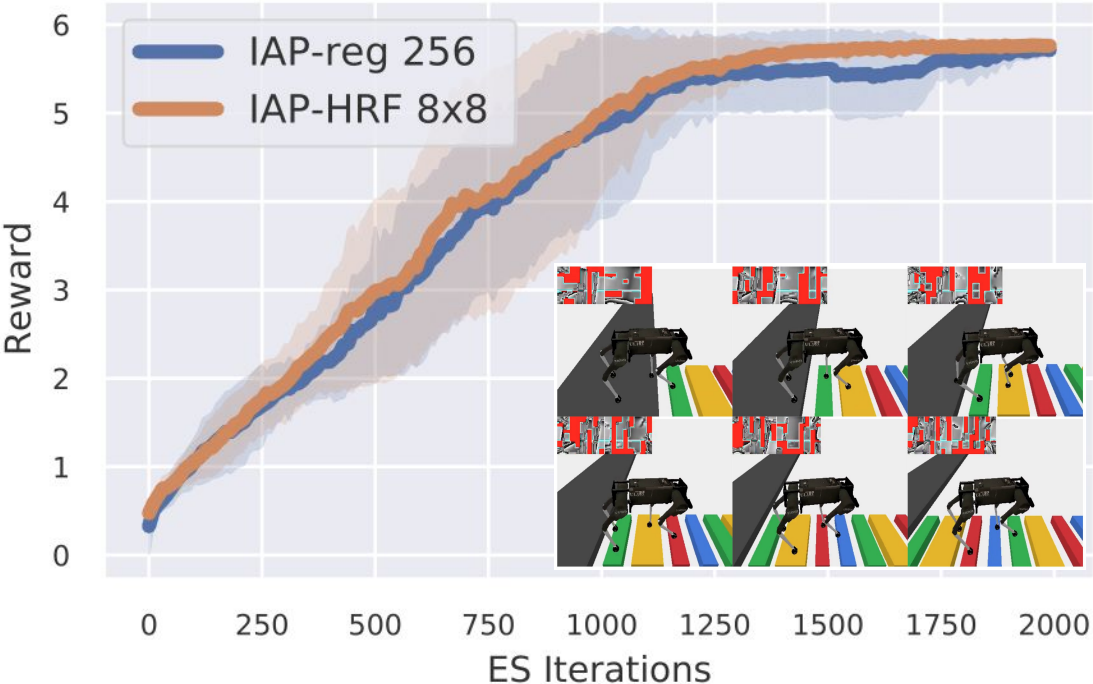
Hybrid Random Features
Krzysztof Choromanski, Haoxian Chen, Han Lin, Yuanzhe Ma, Arijit Sehanobish, Deepali Jain, Michael S Ryoo, Jake Varley, Andy Zeng, Valerii Likhosherstov, Dmitry Kalashnikov, Vikas Sindhwani, Adrian Weller
The International Conference on Learning Representations (ICLR) 2022
PDF

XIRL: Cross-Embodiment Inverse Reinforcement Learning
Kevin Zakka, Andy Zeng, Pete Florence, Jonathan Tompson, Jeannette Bohg, Debidatta Dwibedi
Conference on Robot Learning (CoRL) 2021
★ Best Paper Award Finalist, CoRL ★
Webpage •
PDF •
Code •
Benchmark •
Google AI Blog

Grasping in the Wild: Learning 6DoF Closed-Loop Grasping from Low-Cost Demonstrations
Shuran Song, Andy Zeng, Johnny Lee, Thomas Funkhouser
IEEE International Conference on Intelligent Robots and Systems (IROS) 2020
IEEE Robotics and Automation Letters (RA-L) 2020
Webpage •
PDF

TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
Andy Zeng, Shuran Song, Johnny Lee, Alberto Rodriguez, Thomas Funkhouser
Robotics: Science and Systems (RSS) 2019
IEEE Transactions on Robotics (T-RO) 2020
★ Best Paper Award, T-RO & Best Systems Paper Award, RSS ★
Webpage •
PDF •
Google AI Blog •
New York Times •
IEEE Spectrum
{kind=link}

Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching
Andy Zeng, Shuran Song, Kuan-Ting Yu, Elliott Donlon, Francois R. Hogan, Maria Bauza, Daolin Ma, Orion Taylor, Melody Liu, Eudald Romo, Nima Fazeli, Ferran Alet, Nikhil Chavan Dafle, Rachel Holladay, Isabella Morona, Prem Qu Nair, Druck Green, Ian Taylor, Weber Liu, Thomas Funkhouser, Alberto Rodriguez
IEEE International Conference on Robotics and Automation (ICRA) 2018
The International Journal of Robotics Research (IJRR) 2019
★ 1st Place (Stow Task), Amazon Robotics Challenge 2017 ★
Webpage •
PDF •
Code •
MIT News •
Engadget

3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions
Andy Zeng, Shuran Song, Matthias Nießner, Matthew Fisher, Jianxiong Xiao, Thomas Funkhouser
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017
★ Oral Presentation, CVPR ★
Webpage •
PDF •
Code •
Talk •
2 Minute Papers
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Jacky Liang, Fei Xia, Wenhao Yu, Andy Zeng, Montserrat Gonzalez Arenas, Maria Attarian, Maria Bauza, Matthew Bennice, Alex Bewley, Adil Dostmohamed, Chuyuan Kelly Fu, Nimrod Gileadi, Marissa Giustina, Keerthana Gopalakrishnan, Leonard Hasenclever, Jan Humplik, Jasmine Hsu, Nikhil Joshi, Ben Jyenis, Chase Kew, Sean Kirmani, Tsang-Wei Edward Lee, Kuang-Huei Lee, Assaf Hurwitz Michaely, Joss Moore, Ken Oslund, Dushyant Rao, Allen Ren, Baruch Tabanpour, Quan Vuong, Ayzaan Wahid, Ted Xiao, Ying Xu, Vincent Zhuang, Peng Xu, Erik Frey, Ken Caluwaerts, Tingnan Zhang, Brian Ichter, Jonathan Tompson, Leila Takayama, Vincent Vanhoucke, Izhak Shafran, Maja Mataric, Dorsa Sadigh, Nicolas Heess, Kanishka Rao, Nik Stewart, Jie Tan, Carolina Parada
Robotics: Science and Systems (RSS) 2024
Webpage •
PDF •
Code
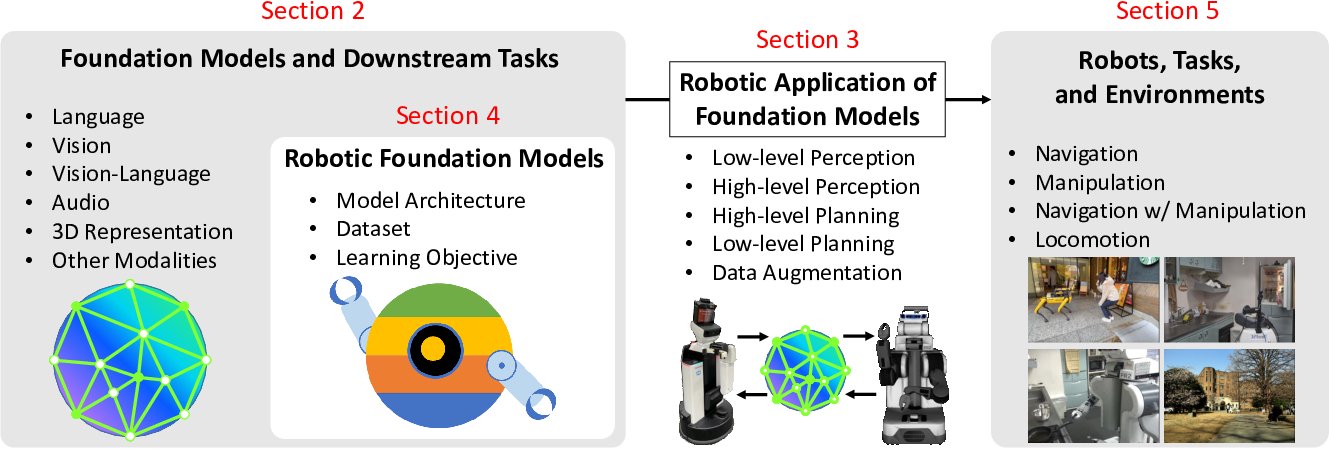
Real-World Robot Applications of Foundation Models: A Review
Kento Kawaharazuka, Tatsuya Matsushima, Andrew Gambardella, Jiaxian Guo, Chris Paxton, Andy Zeng
Advanced Robotics (AR) 2024
PDF
Generative Expressive Robot Behaviors using Large Language Models
Karthik Mahadevan, Jonathan Chien, Noah Brown, Zhuo Xu, Carolina Parada, Fei Xia, Andy Zeng, Leila Takayama, Dorsa Sadigh
ACM/IEEE International Conference on Human Robot Interaction (HRI) 2024
★ Best Paper Award, HRI ★
Webpage •
PDF
Chain of Code: Reasoning with a Language Model-Augmented Code Emulator
Chengshu Li, Jacky Liang, Andy Zeng, Xinyun Chen, Karol Hausman, Dorsa Sadigh, Sergey Levine, Li Fei-Fei, Fei Xia, Brian Ichter
International Conference on Machine Learning (ICML) 2024
★ Oral Presentation, ICML ★
Webpage •
PDF •
Code
Video Language Planning
Yilun Du, Mengjiao Yang, Pete Florence, Fei Xia, Ayzaan Wahid, Brian Ichter, Pierre Sermanet, Tianhe Yu, Pieter Abbeel, Joshua B. Tenenbaum, Leslie Kaelbling, Andy Zeng, Jonathan Tompson
International Conference on Learning Representations (ICLR) 2024
Webpage •
PDF •
Code
Large Language Models as General Pattern Machines
Suvir Mirchandani, Fei Xia, Pete Florence, Brian Ichter, Danny Driess, Montserrat Gonzalez Arenas, Kanishka Rao, Dorsa Sadigh, Andy Zeng
Conference on Robot Learning (CoRL) 2023
Webpage •
PDF •
Code
Robots That Ask For Help: Uncertainty Alignment for Large Language Model Planners
Allen Z. Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, Fei Xia, Jake Varley, Zhenjia Xu, Dorsa Sadigh, Andy Zeng, Anirudha Majumdar
Conference on Robot Learning (CoRL) 2023
★ Oral Presentation, Best Student Paper Award, CoRL ★
Webpage •
PDF •
Video
Language to Rewards for Robotic Skill Synthesis
Wenhao Yu, Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Jan Humplik, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng, Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan, Yuval Tassa, Fei Xia
Conference on Robot Learning (CoRL) 2023
★ Oral Presentation, CoRL ★
Webpage •
PDF •
Video
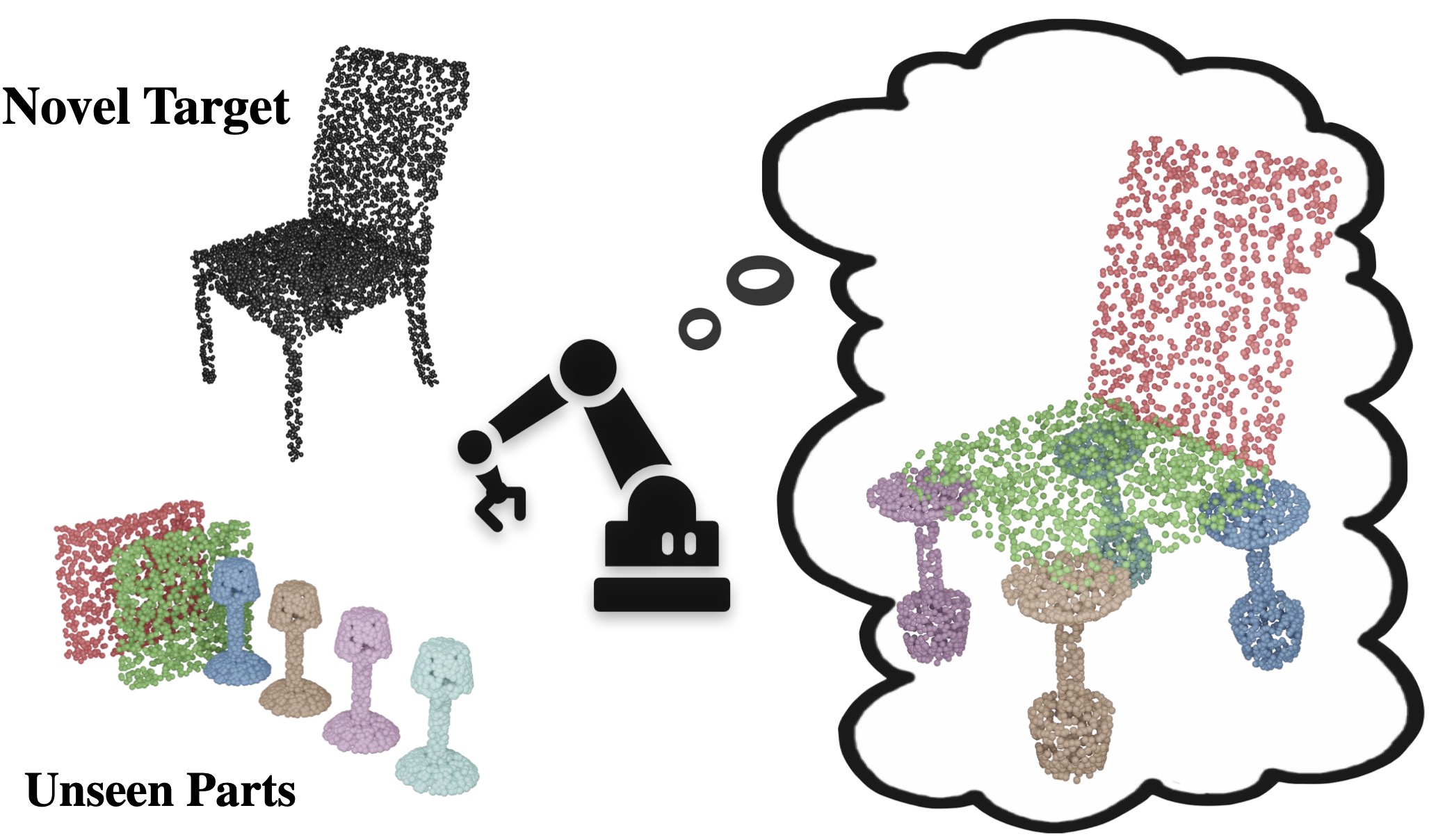
Rearrangement Planning for General Part Assembly
Yulong Li, Andy Zeng, Shuran Song
Conference on Robot Learning (CoRL) 2023
★ Oral Presentation, CoRL ★
Webpage •
PDF •
Video •
Code

CALAMARI: Contact-Aware and Language conditioned spatial Action MApping for contact-RIch manipulation
Youngsun Wi, Mark Van der Merwe, Pete Florence, Andy Zeng, Nima Fazeli
Conference on Robot Learning (CoRL) 2023
PDF
TidyBot: Personalized Robot Assistance with Large Language Models
Jimmy Wu, Rika Antonova, Adam Kan, Marion Lepert, Andy Zeng, Shuran Song, Jeannette Bohg, Szymon Rusinkiewicz, Thomas Funkhouser
IEEE International Conference on Intelligent Robots and Systems (IROS) 2023
Autonomous Robots 2023
Webpage •
PDF •
Code
Modular Visual Question Answering via Code Generation
Sanjay Subramanian, Medhini Narasimhan, Kushal Khangaonkar, Kevin Yang, Arsha Nagrani, Cordelia Schmid, Andy Zeng, Trevor Darrell, Dan Klein
Association for Computational Linguistics (ACL) 2023
PDF •
Code •
Google AI Blog
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, Pete Florence
International Conference on Machine Learning (ICML) 2023
Webpage •
PDF •
Demo •
Google AI Blog
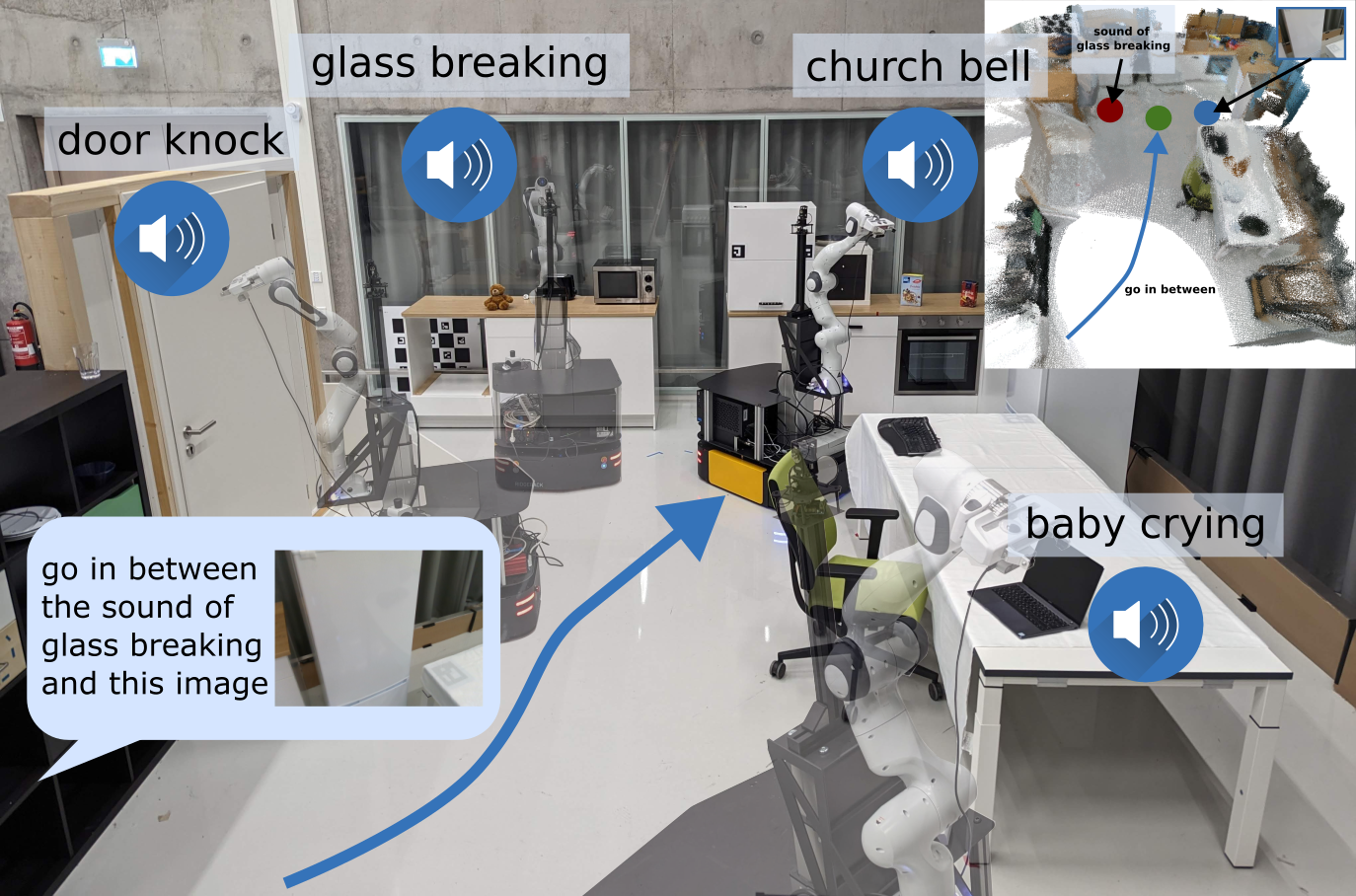
Audio Visual Language Maps for Robot Navigation
Chenguang Huang, Oier Mees, Andy Zeng, Wolfram Burgard
International Symposium on Experimental Robotics (ISER) 2023
Webpage •
PDF •
Colab
Grounded Decoding: Guiding Text Generation with Grounded Models for Robot Control
Wenlong Huang, Fei Xia, Dhruv Shah, Danny Driess, Andy Zeng, Yao Lu, Pete Florence, Igor Mordatch, Sergey Levine, Karol Hausman, Brian Ichter
Conference on Neural Information Processing Systems (NeurIPS) 2023
Webpage •
PDF •
Video
Code as Policies: Language Model Programs for Embodied Control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
IEEE International Conference on Robotics and Automation (ICRA) 2023
★ Outstanding Learning Paper Award, ICRA ★
Webpage •
PDF •
Code •
Colab •
Google AI Blog •
TechCrunch •
AXIOS
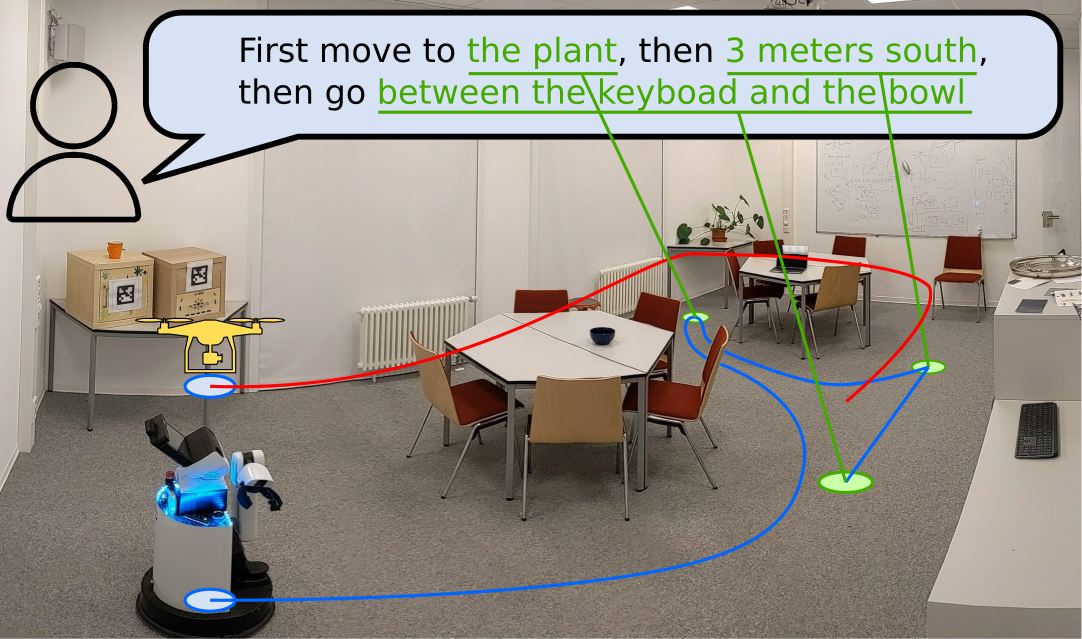
Visual Language Maps for Robot Navigation
Chenguang Huang, Oier Mees, Andy Zeng, Wolfram Burgard
IEEE International Conference on Robotics and Automation (ICRA) 2023
Webpage •
PDF •
Code •
Google AI Blog
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
Andy Zeng, Maria Attarian, Brian Ichter, Krzysztof Choromanski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, Pete Florence
International Conference on Learning Representations (ICLR) 2023
★ Oral Presentation, ICLR ★
Webpage •
PDF •
Code
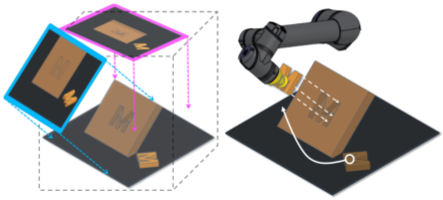
MIRA: Mental Imagery for Robotic Affordances
Lin Yen-Chen, Pete Florence, Andy Zeng, Jonathan T. Barron, Yilun Du, Wei-Chiu Ma, Anthony Simeonov, Alberto Rodriguez Garcia, Phillip Isola
Conference on Robot Learning (CoRL) 2022
Webpage •
PDF
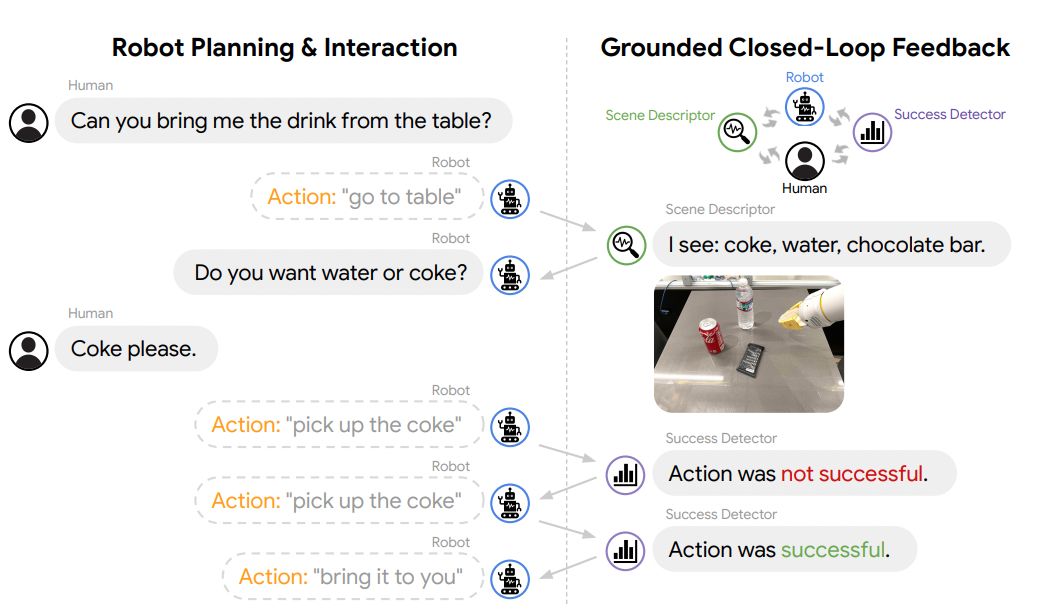
Inner Monologue: Embodied Reasoning through Planning with Language Models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, Brian Ichter
Conference on Robot Learning (CoRL) 2022
Webpage •
PDF •
2 Minute Papers

VIRDO++: Real-World, Visuo-Tactile Dynamics and Perception of Deformable Objects
Youngsun Wi, Andy Zeng, Pete Florence, Nima Fazeli
Conference on Robot Learning (CoRL) 2022
Webpage •
PDF
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kuang-Huei Lee, Sergey Levine, Yao Lu, Linda Luu, Carolina Parada, Peter Pastor, Jornell Quiambao, Kanishka Rao, Jarek Rettinghouse, Diego Reyes, Pierre Sermanet, Nicolas Sievers, Clayton Tan, Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Mengyuan Yan, Andy Zeng
Conference on Robot Learning (CoRL) 2022
★ Oral Presentation, Special Innovation Award, CoRL ★
Webpage •
PDF •
Code •
Google AI Blog •
Wired •
Washington Post •
CNET

Learning to Fold Real Garments with One Arm: A Case Study in Cloud-Based Robotics Research
Ryan Hoque, Kaushik Shivakumar, Shrey Aeron, Gabriel Deza, Aditya Ganapathi, Adrian Wong, Johnny Lee, Andy Zeng, Vincent Vanhoucke, Ken Goldberg
IEEE International Conference on Intelligent Robots and Systems (IROS) 2022
Webpage •
PDF •
Code
Algorithms and Systems for Manipulating Multiple Objects
Zherong Pan, Andy Zeng, Yunzhu Li, Jingjin Yu, Kris Hauser
IEEE Transactions on Robotics (T-RO) 2022
PDF

Learning Pneumatic Non-Prehensile Manipulation with a Mobile Blower
Jimmy Wu, Xingyuan Sun, Andy Zeng, Shuran Song, Szymon Rusinkiewicz, Thomas Funkhouser
IEEE International Conference on Intelligent Robots and Systems (IROS) 2022
IEEE Robotics and Automation Letters (RA-L) 2022
Webpage •
PDF •
Code
Multiscale Sensor Fusion and Continuous Control with Neural CDEs
Sumeet Singh, Francis McCann Ramirez, Jacob Varley, Andy Zeng, Vikas Sindhwani
IEEE International Conference on Intelligent Robots and Systems (IROS) 2022
PDF

Implicit Kinematic Policies: Unifying Joint and Cartesian Action Spaces in End-to-End Robot Learning
Aditya Ganapathi, Pete Florence, Jake Varley, Kaylee Burns, Ken Goldberg, Andy Zeng
IEEE International Conference on Robotics and Automation (ICRA) 2022
Webpage •
PDF
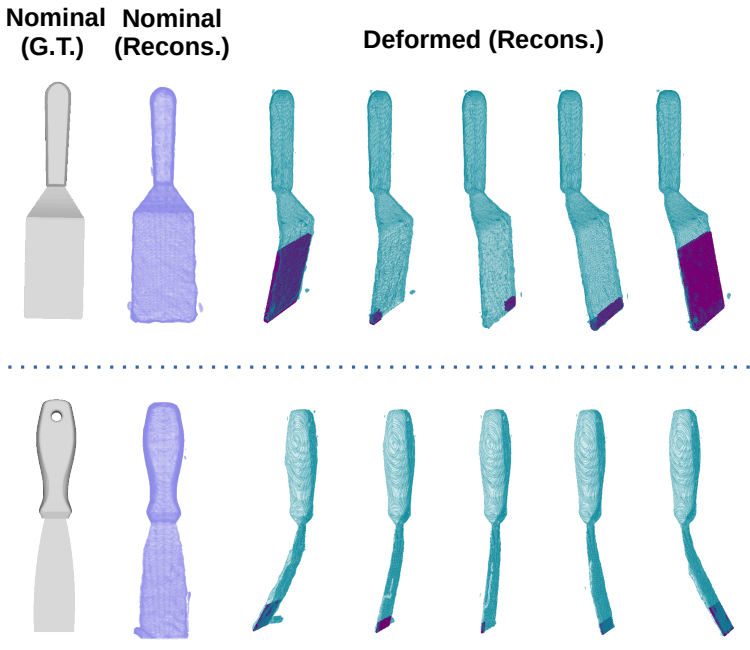
VIRDO: Visio-Tactile Implicit Representations of Deformable Objects
Youngsun Wi, Pete Florence, Andy Zeng, Nima Fazeli
IEEE International Conference on Robotics and Automation (ICRA) 2022
PDF •
Code
Multi-Task Learning with Sequence-Conditioned Transporter Networks
Michael H. Lim, Andy Zeng, Brian Ichter, Maryam Bandari, Erwin Coumans, Claire Tomlin, Stefan Schaal, Aleksandra Faust
IEEE International Conference on Robotics and Automation (ICRA) 2022
PDF
Hybrid Random Features
Krzysztof Choromanski, Haoxian Chen, Han Lin, Yuanzhe Ma, Arijit Sehanobish, Deepali Jain, Michael S Ryoo, Jake Varley, Andy Zeng, Valerii Likhosherstov, Dmitry Kalashnikov, Vikas Sindhwani, Adrian Weller
The International Conference on Learning Representations (ICLR) 2022
PDF
Implicit Behavioral Cloning
Pete Florence, Corey Lynch, Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, Jonathan Tompson
Conference on Robot Learning (CoRL) 2021
Webpage •
PDF •
Code •
Google AI Blog
XIRL: Cross-Embodiment Inverse Reinforcement Learning
Kevin Zakka, Andy Zeng, Pete Florence, Jonathan Tompson, Jeannette Bohg, Debidatta Dwibedi
Conference on Robot Learning (CoRL) 2021
★ Best Paper Award Finalist, CoRL ★
Webpage •
PDF •
Code •
Benchmark •
Google AI Blog
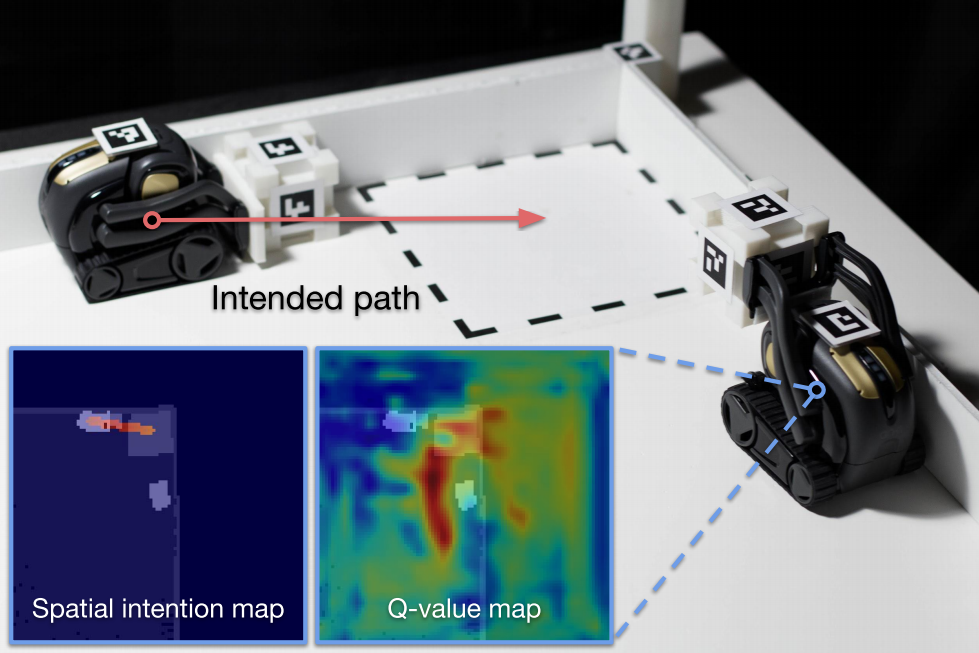
Spatial Intention Maps for Multi-Agent Mobile Manipulation
Jimmy Wu, Xingyuan Sun, Andy Zeng, Shuran Song, Szymon Rusinkiewicz, Thomas Funkhouser
IEEE International Conference on Robotics and Automation (ICRA) 2021
Webpage •
PDF •
Code •
Princeton News
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks
Daniel Seita, Pete Florence, Jonathan Tompson, Erwin Coumans, Vikas Sindhwani, Ken Goldberg, Andy Zeng
IEEE International Conference on Robotics and Automation (ICRA) 2021
Webpage •
PDF •
Code •
Google AI Blog
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
Andy Zeng, Pete Florence, Jonathan Tompson, Stefan Welker, Jonathan Chien, Maria Attarian, Travis Armstrong, Ivan Krasin, Dan Duong, Vikas Sindhwani, Johnny Lee
Conference on Robot Learning (CoRL) 2020
★ Plenary Talk, Best Paper Presentation Award Finalist, CoRL ★
Webpage •
PDF •
Code •
Google AI Blog •
VentureBeat
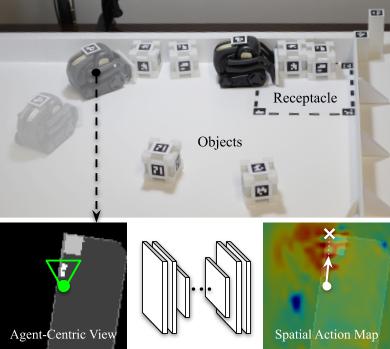
Spatial Action Maps for Mobile Manipulation
Jimmy Wu, Xingyuan Sun, Andy Zeng, Shuran Song, Johnny Lee, Szymon Rusinkiewicz, Thomas Funkhouser
Robotics: Science and Systems (RSS) 2020
Webpage •
PDF •
Code •
Princeton News
Grasping in the Wild: Learning 6DoF Closed-Loop Grasping from Low-Cost Demonstrations
Shuran Song, Andy Zeng, Johnny Lee, Thomas Funkhouser
IEEE International Conference on Intelligent Robots and Systems (IROS) 2020
IEEE Robotics and Automation Letters (RA-L) 2020
Webpage •
PDF

Form2Fit: Learning Shape Priors for Generalizable Assembly from Disassembly
Kevin Zakka, Andy Zeng, Johnny Lee, Shuran Song
IEEE International Conference on Robotics and Automation (ICRA) 2020
★ Best Paper in Automation Award Finalist, ICRA ★
Webpage •
PDF •
Code •
Google AI Blog •
VentureBeat •
2 Minute Papers
ClearGrasp: 3D Shape Estimation of Transparent Objects for Manipulation
Shreeyak Sajjan, Matthew Moore, Mike Pan, Ganesh Nagaraja, Johnny Lee, Andy Zeng, Shuran Song
IEEE International Conference on Robotics and Automation (ICRA) 2020
Webpage •
PDF •
Code •
Dataset •
Google AI Blog •
VentureBeat
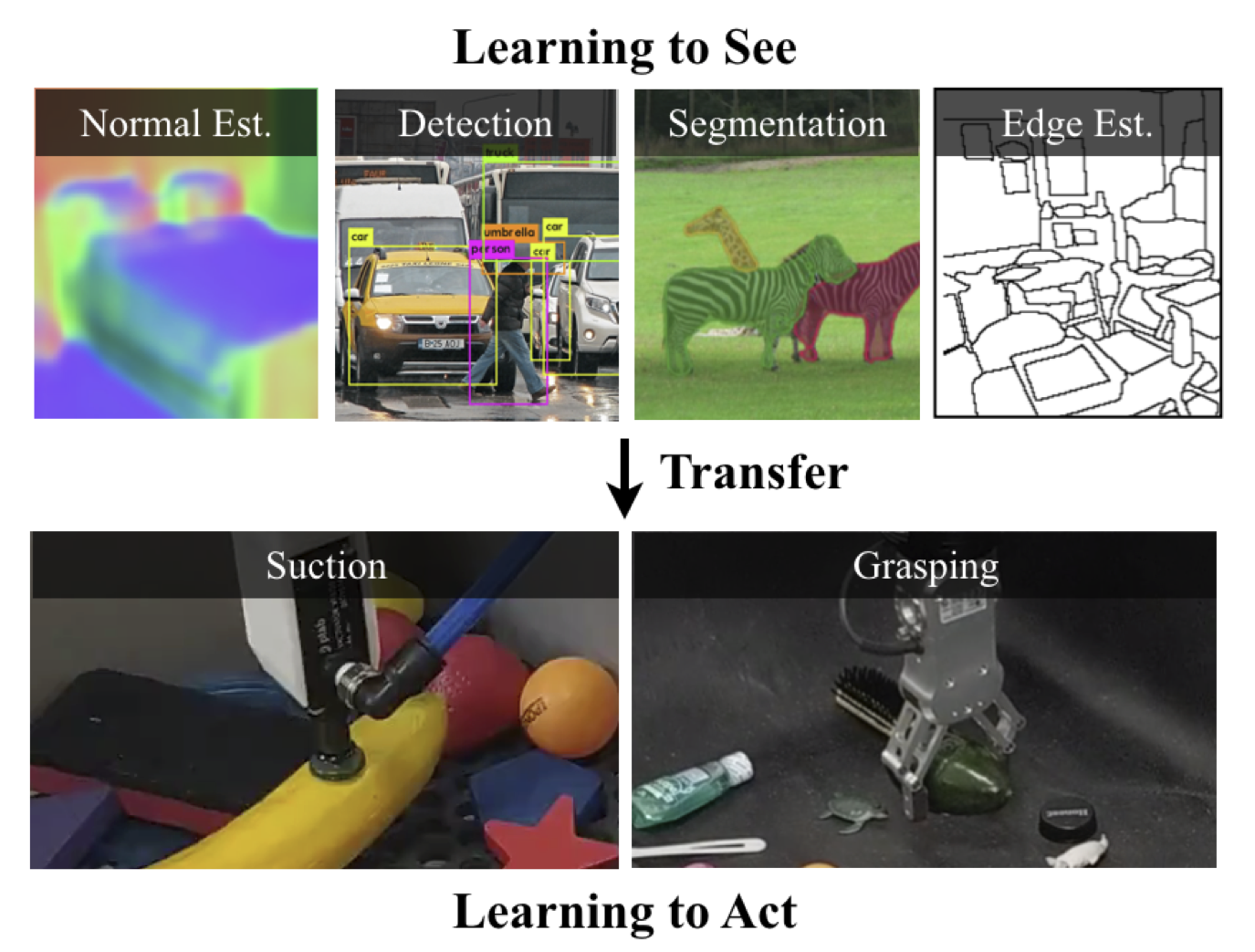
Learning to See before Learning to Act: Visual Pre-training for Manipulation
Lin Yen-Chen, Andy Zeng, Shuran Song, Phillip Isola, Tsung-Yi Lin
IEEE International Conference on Robotics and Automation (ICRA) 2020
Webpage •
PDF •
Code •
Google AI Blog •
VentureBeat
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
Andy Zeng, Shuran Song, Johnny Lee, Alberto Rodriguez, Thomas Funkhouser
Robotics: Science and Systems (RSS) 2019
IEEE Transactions on Robotics (T-RO) 2020
Featured on the front page of The New York Times Business!
★ King-Sun Fu Memorial Best Paper Award, T-RO ★
★ Best Systems Paper Award, RSS ★
★ Best Student Paper Award Finalist, RSS ★
Webpage •
PDF •
Google AI Blog •
New York Times •
IEEE Spectrum

DensePhysNet: Learning Dense Physical Object Representations via Multi-step Dynamic Interactions
Zhenjia Xu, Jiajun Wu, Andy Zeng, Joshua B. Tenenbaum, Shuran Song
Robotics: Science and Systems (RSS) 2019
Webpage •
PDF •
Code

Learning Synergies between Pushing and Grasping with Self-supervised Deep Reinforcement Learning
Andy Zeng, Shuran Song, Stefan Welker, Johnny Lee, Alberto Rodriguez, Thomas Funkhouser
IEEE International Conference on Intelligent Robots and Systems (IROS) 2018
★ Best Cognitive Robotics Paper Award Finalist, IROS ★
Webpage •
PDF •
Code •
2 Minute Papers
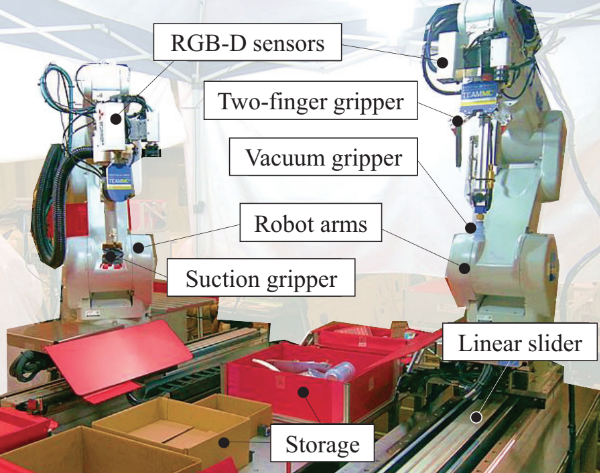
What are the Important Technologies for Bin Picking? Technology Analysis of Robots in Competitions Based on a Set of Performance Metrics
Masahiro Fujita, Yukiyasu Domae, Akio Noda, Gustavo Alfonso Garcia Ricardez, Tatsuya Nagatani, Andy Zeng, Shuran Song, Alberto Rodriguez, Albert Causo, I-Ming Chen, Tsukasa Ogasawara
Advanced Robotics (Journal) 2019
★ Japan Factory Automation (FA) Foundation Paper Award ★
Webpage •
PDF
Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching
Andy Zeng, Shuran Song, Kuan-Ting Yu, Elliott Donlon, Francois R. Hogan, Maria Bauza, Daolin Ma, Orion Taylor, Melody Liu, Eudald Romo, Nima Fazeli, Ferran Alet, Nikhil Chavan Dafle, Rachel Holladay, Isabella Morona, Prem Qu Nair, Druck Green, Ian Taylor, Weber Liu, Thomas Funkhouser, Alberto Rodriguez
IEEE International Conference on Robotics and Automation (ICRA) 2018
The International Journal of Robotics Research (IJRR) 2019
★ Best Systems Paper Award, Amazon Robotics ★
★ 1st Place (Stow Task), Amazon Robotics Challenge 2017 ★
Webpage •
PDF •
Code •
Journal (IJRR) •
MIT News •
Engadget
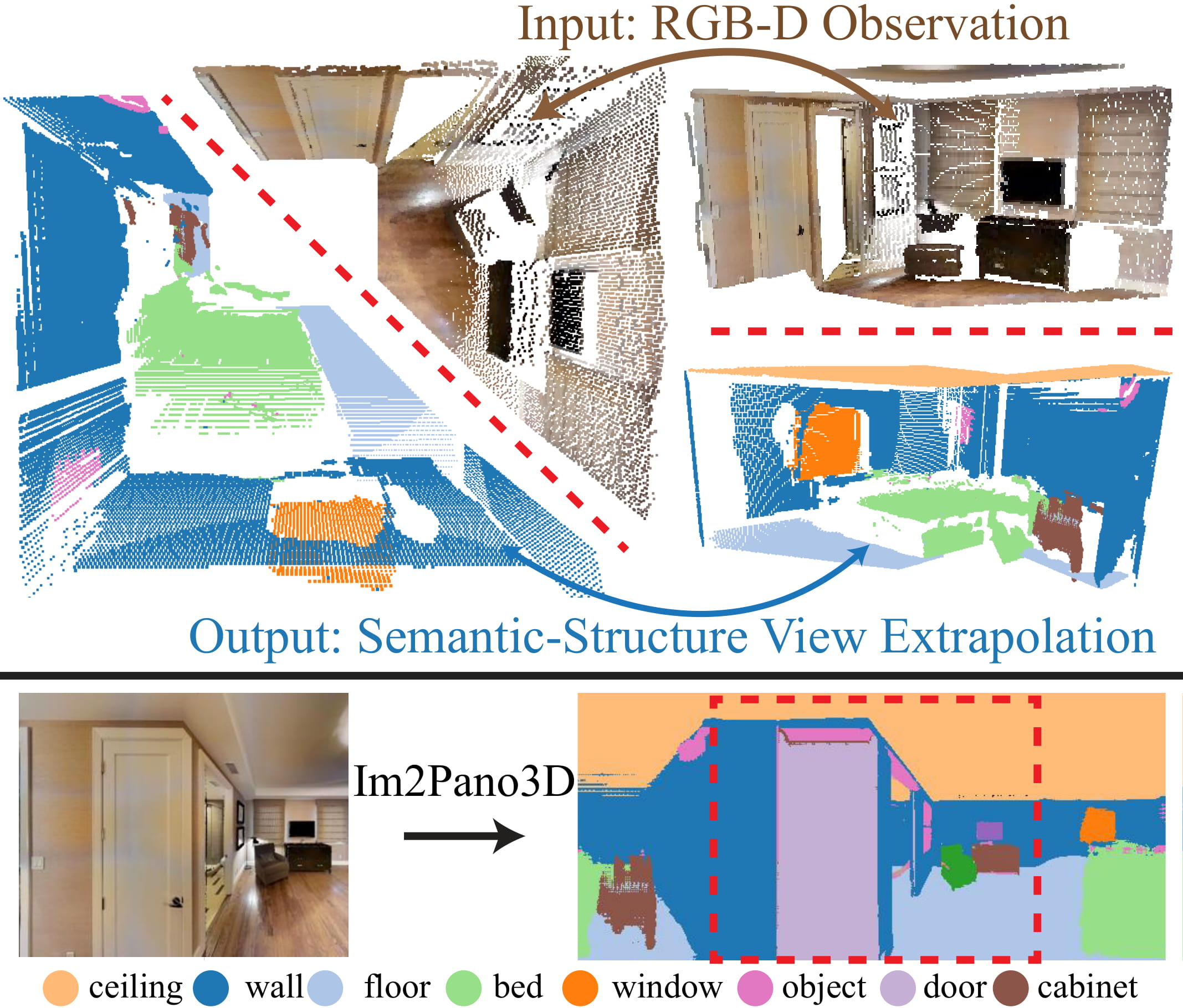
Im2Pano3D: Extrapolating 360° Structure and Semantics Beyond the Field of View
Shuran Song, Andy Zeng, Angel X. Chang, Manolis Savva, Silvio Savarese, Thomas Funkhouser
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018
★ Oral Presentation, CVPR ★
Webpage •
PDF
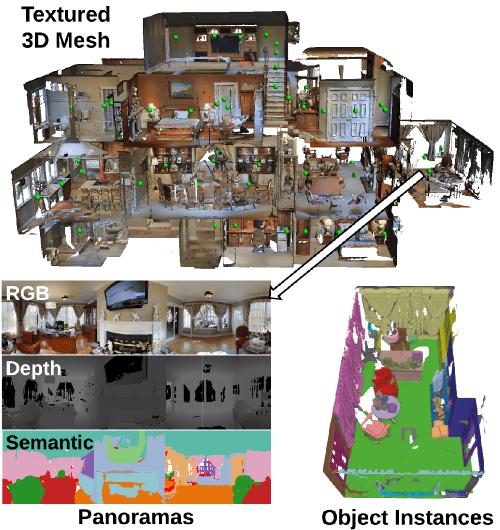
Matterport3D: Learning from RGB-D Data in Indoor Environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Nießner, Manolis Savva, Shuran Song, Andy Zeng, Yinda Zhang
IEEE International Conference on 3D Vision (3DV) 2017
Webpage •
PDF •
Code •
Matterport Blog
3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions
Andy Zeng, Shuran Song, Matthias Nießner, Matthew Fisher, Jianxiong Xiao, Thomas Funkhouser
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017
★ Oral Presentation, CVPR ★
Webpage •
PDF •
Code •
Talk •
2 Minute Papers

Semantic Scene Completion from a Single Depth Image
Shuran Song, Fisher Yu, Andy Zeng, Angel X. Chang, Manolis Savva, Thomas Funkhouser
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017
★ Oral Presentation, CVPR ★
Webpage •
PDF •
SUNCG Dataset •
Code •
Talk •
2 Minute Papers

Multi-view Self-supervised Deep Learning for 6D Pose Estimation in the Amazon Picking Challenge
Andy Zeng, Kuan-Ting Yu, Shuran Song, Daniel Suo, Ed Walker Jr., Alberto Rodriguez, Jianxiong Xiao
IEEE International Conference on Robotics and Automation (ICRA) 2017
★ 3rd Place, Amazon Robotics Challenge 2016 ★
Webpage •
PDF •
Shelf & Tote Dataset •
Code
2026
CES K-Innovation Night2024
UIUC CSL Student Conference2023
EMNLP Workshop on RoboNLP2021
CVPR Workshop on 3D Vision and Robotics2020
RSS Workshop on Self-Supervised Robot Learning2019
Amazon Research Robotics Symposium2018
RE·WORK Deep Learning for Robotics Summit2025
Advanced Robotics (AR) Best Survey Paper Award2024
IEEE Robotics and Automation (RAS) Early Career Award2023
Conference on Robot Learning (CoRL) Best Student Paper Award{kind=link}
{kind=link}
2022
Conference on Robot Learning (CoRL) Special Innovation Award{kind=link}
2021
Conference on Robot Learning (CoRL) Best Paper Award Finalist2020
IEEE Transactions on Robotics (T-RO) Best Paper Award2019
New York Times article "A New Lab Full of Fast Learners" (100+ articles)2018
Honored to be a recipient of the Princeton SEAS Award for Excellence2015
Honored to be a recipient of the Gordon Y.S. Wu Fellowship in Engineering and Wu Prize2015+
Reviewer, T-RO, RSS, CoRL, IJRR, RA-L, ICRA, NeurIPS, CVPR, IROS, ECCV, ICCV